Python asyncio pipeline setup
Python asyncio can be quite tricky to work with. We'll look at constructing a very basic pipeline to help with those IO heavy jobs.
When dealing with a lot of IO a naive program will idle a lot, waiting on resources. Using Python asyncio a process can continue working on other parts of your program while it's waiting to, say, fetch something from disc. All the asyncio code can quickly clutter the most basic of programs, so I found it helpful to order the program into a clear pipeline if possible.
Here we will look at such a pipeline. Starting out with a few basic examples, and finishing with a more realistic use case.
Note that I've found that asyncio is only of use for IO bottlenecked programs.
Technically I think CPU heavy loads can be parallelized as well with ThreadPoolExecutor, but I've never gotten any good results.
If you have a CPU heavy load I suggest you wrap the entire program in something else (multiprocessing)
or (if possible) switch to a language more suited for the task.
Basic setup
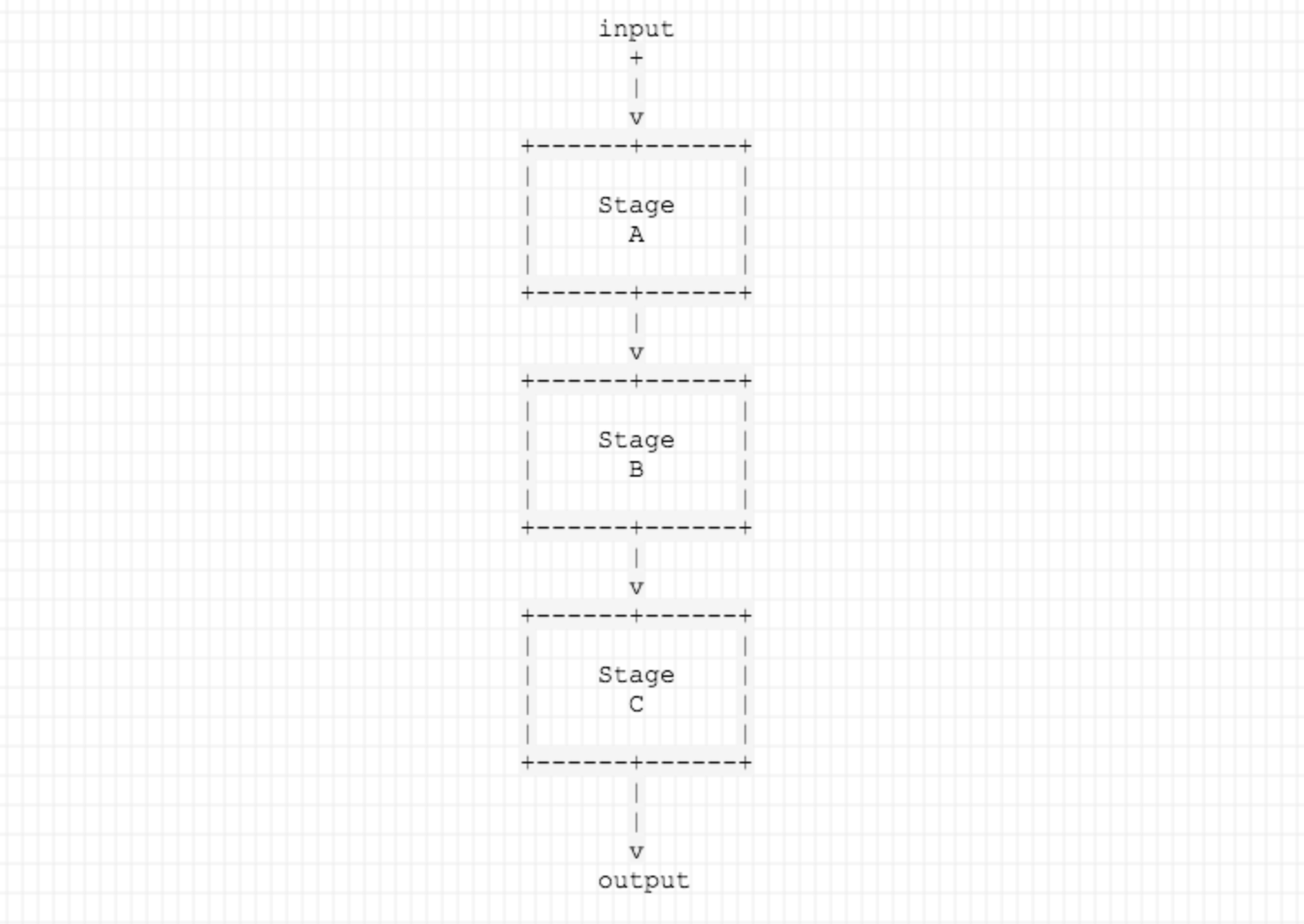
To start out, we'll look at a program that takes a string and changes it to upper case letter by letter.
It consists of
- Stage A, sends word, letter by letter
- Stage B, changes letter to uppercase and forwards it
- Stage C, accumulates result
Here's the code (see gist):
"""
Example program for basic asyncio pipeline.
Program takes string as input and converts it to upper case.
For sake of simplicity missing some "features", most notably error handling is absent.
Errors will silenty prevent program completion in many cases.
"""
import asyncio
from dataclasses import dataclass
@dataclass()
class DataAB:
letter: str
@dataclass()
class DataBC:
letter: str
upper: str
result = ""
async def do_stepA(queue_out, input):
for letter in input:
print(f'A, sending {letter}')
await queue_out.put(DataAB(letter))
async def do_stepB(queue_in, queue_out):
while True:
data: DataAB = await queue_in.get()
# perform actual step
letter = data.letter
upper = letter.upper()
print(f'B, processed {upper}')
await queue_out.put(DataBC(letter, upper))
queue_in.task_done()
async def do_stepC(queue_in):
global result
while True:
data: DataBC = await queue_in.get()
# perform actual step
letter = data.letter
upper = data.upper
print(f'C, {letter} changed to {upper}')
result += upper
queue_in.task_done()
async def main():
pipeline_in = 'hello world'
print(f'converting to upper case: {pipeline_in}')
queue_AB = asyncio.Queue()
queue_BC = asyncio.Queue()
stepA = asyncio.create_task(do_stepA(queue_AB, pipeline_in))
stepB = asyncio.create_task(do_stepB(queue_AB, queue_BC))
stepC = asyncio.create_task(do_stepC(queue_BC))
await stepA
print('step A done')
await queue_AB.join()
print('queue A - B done')
stepB.cancel() # no more date is going to show up at B
await queue_BC.join()
print('queue B - C done')
stepC.cancel() # no more date is going to show up at C
print(f'main complete, result: {result}')
asyncio.run(main())
print('program complete')
For the input "hello" this program produces the following output:
converting to upper case: hello
A, sending h
A, sending e
A, sending l
A, sending l
A, sending o
B, processed H
B, processed E
B, processed L
B, processed L
B, processed O
C, h changed to H
C, e changed to E
C, l changed to L
C, l changed to L
C, o changed to O
step A done
queue A - B done
queue B - C done
main complete, result: HELLO
program complete
Note that every stage in te pipeline is serverd by a single task. And note that the input is passed through the pipeline in order.
Waiting
When we add a random sleep to the stages the output is less clean, but still ordered.
async def sleep_about(t: float):
sleep_s = t + 0.5 * random.random()
await asyncio.sleep(sleep_s)
async def do_stepA(queue_out, input):
for letter in input:
await sleep_about(0.1)
print(f'A, sending {letter}')
await queue_out.put(DataAB(letter))
async def do_stepB(queue_in, queue_out):
while True:
data: DataAB = await queue_in.get()
# perform actual step
letter = data.letter
upper = letter.upper()
await sleep_about(1)
print(f'B, processed {upper}')
await queue_out.put(DataBC(letter, upper))
queue_in.task_done()
The full program can be found here
For the input "hello" the result now changes between runs, one such output is:
converting to upper case: hello
A, sending h
A, sending e
A, sending l
B, processed H
C, h changed to H
A, sending l
A, sending o
step A done
B, processed E
C, e changed to E
B, processed L
C, l changed to L
B, processed L
C, l changed to L
B, processed O
C, o changed to O
queue A - B done
queue B - C done
main complete, result: HELLO
program complete
Stage level concurrency
These example thus far have had a single task per stage. Even so for heavy IO programs you will likely see a speedup because there is still work available while waiting for IO. In certain cases it is possible to perform multiple of the same IO operations at the same time. Here it may pay of to run multiple tasks for the same stage.
Task B for example can be served by 3 tasks using:
async def main():
...
stepA = asyncio.create_task(do_stepA(queue_AB, pipeline_in))
stepsB = [
asyncio.create_task(do_stepB(queue_AB, queue_BC, 1)),
asyncio.create_task(do_stepB(queue_AB, queue_BC, 2)),
asyncio.create_task(do_stepB(queue_AB, queue_BC, 3)),
]
stepC = asyncio.create_task(do_stepC(queue_BC))
await queue_AB.join()
print('queue A - B done')
for step in stepsB:
step.cancel() # no more date is going to show up at B
...
For the full code see gist.
If a stage execution time can vary, the order is now no longer guaranteed. This can cause garbled output such as:
converting to upper case: hello
A, sending h
A, sending e
A, sending l
A, sending l
A, sending o
step A done
B 1, processed H
C, h changed to H
B 2, processed E
C, e changed to E
B 3, processed L
C, l changed to L
B 2, processed O
C, o changed to O
B 1, processed L
C, l changed to L
queue A - B done
queue B - C done
main complete, result: HELOL
program complete
"Parallel" downloads
One of the main use cases for asyncio is parallel network requests. Network request often have long wait time during which other processing can occur. Furthermore by using asyncio for network requests, multiple requests can run in parallel.
A typical scenario requires fetching a list of ids/objects from a list end point and calling each individual detail end point. The example here fetches the sink rates from an open API of the Amsterdam municipality. The sink rate of meetbouten (building "sink" rate measurement device) is retrieved in the serial and concurrent example.
Stage one gets a list of ids from the list end point:
...
r = await client.get(f'https://api.data.amsterdam.nl/meetbouten/meetbout/?page_size={min(100, N)}')
data = json.loads(r.content)
meetbouten = data.get('results')
ids = [x.get('id') for x in meetbouten[:N]]
...
Next for each id a detail end point is called using:
...
import httpx
client = httpx.AsyncClient()
...
...
id = data.meetbout_id
r = await client.get(f'https://api.data.amsterdam.nl/meetbouten/meetbout/{id}/')
data = json.loads(r.content)
zakkingsnelheid = data.get("zakkingssnelheid")
....
Given that this program is mostly network bound, a large increase in speed is obtained by performing many detail calls in parallel. A quick benchmark yields the following results:
| Program | Time (in seconds) | Speedup |
|---|---|---|
| Serial | 13.4 | |
| Asyncio B concurency 1 | 13.0 | 1.03 |
| Asyncio B concurency 2 | 6.6 | 2.03 |
| Asyncio B concurency 4 | 3.4 | 3.94 |
| Asyncio B concurency 8 | 1.8 | 7.44 |
| Asyncio B concurency 16 | 1.3 | 10.30 |
For this example a single task serving the detail fetch stage performs equal to a serial program. Performing the detail fetch concurrently however scales nearly linearly with the number of tasks deticated to the detail stage. The speedup drops off after 8 parallel network calls.
So using asyncio we can get some great performance gains for these high latency IO tasks. And by structuring the code as a pipeline the added logic of asyncio is kept in check.
Further reading and insipration
- Other pipeline setup, using a more implicit pipeline flow.
- Asyncio producer consumer example.
- Multiprocessing pipeline example